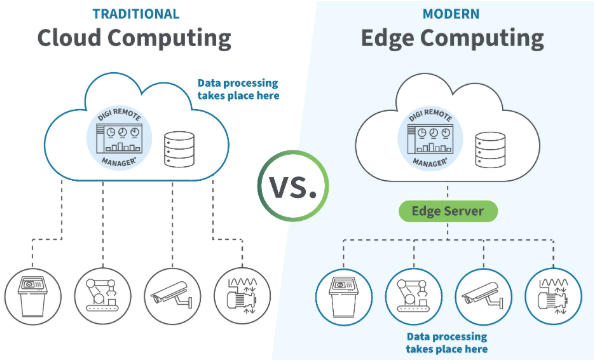
In industrial data acquisition projects, one of the earliest—and most misunderstood—decisions is whether data should be processed at the edge or in the cloud.
Many teams default to cloud-first architectures, only to discover latency, reliability, and cost issues after deployment. Others over-invest in edge systems that limit visibility and scalability.
This article explains the real differences between edge and cloud data acquisition, when each approach makes sense, and why modern industrial systems increasingly rely on hybrid architectures.
Understanding Edge and Cloud in Industrial Data Acquisition
Before comparing them, it is important to clarify what “edge” and “cloud” actually mean in industrial contexts.
What Is Edge Data Acquisition?
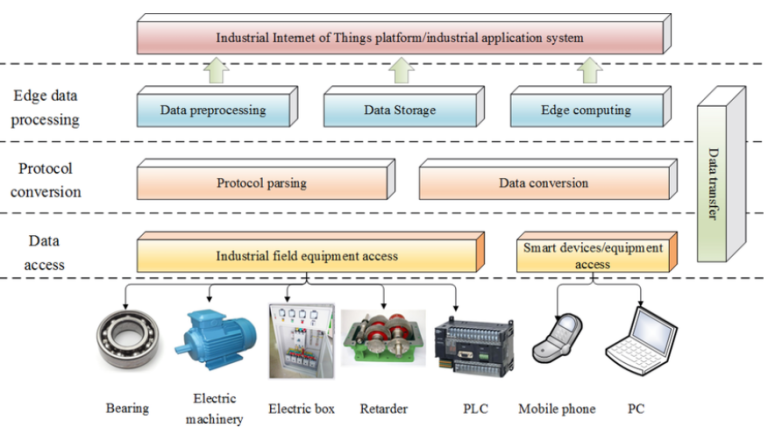
Edge data acquisition refers to collecting and processing industrial data close to the source, typically using:
- Industrial gateways
- Embedded controllers
- Edge computers
At the edge, systems can:
- Read data from PLCs and sensors
- Perform preprocessing and filtering
- Execute local logic and alarms
- Buffer data during network outages
Edge systems operate inside the factory or site, independent of constant internet access.
What Is Cloud Data Acquisition?
Cloud data acquisition centralizes data processing in remote servers.
Typical characteristics:
- Data is transmitted over the network
- Processing happens in cloud platforms
- Storage and analytics are centralized
- Dashboards are accessed via web interfaces
Cloud systems excel at aggregation, analytics, and long-term storage, but depend heavily on connectivity.
Key Differences: Edge vs Cloud Data Acquisition
1. Latency and Real-Time Response
Edge data acquisition
- Millisecond-level response
- Ideal for alarms and control-related logic
- No dependency on external networks
Cloud data acquisition
- Higher latency
- Not suitable for real-time reactions
- Dependent on network stability
For time-critical industrial processes, edge processing is non-negotiable.
2. Reliability and Network Dependency
Industrial networks are often:
- Unstable
- Bandwidth-limited
- Segmented for security
Edge-based systems continue operating even when connectivity is lost. Cloud-only architectures may lose data or visibility during outages unless complex buffering mechanisms are added.
Reliability is a major reason why industrial data acquisition cannot be cloud-only.
3. Data Volume and Bandwidth Costs
Industrial environments generate massive data volumes:
- High-frequency sensor data
- Continuous machine states
- Image or video streams
Sending all raw data to the cloud:
- Consumes bandwidth
- Increases operational costs
- Creates unnecessary storage overhead
Edge data acquisition allows local filtering and aggregation, sending only meaningful data upstream.
4. Scalability and Centralized Analytics
This is where cloud systems excel.
Cloud-based data acquisition supports:
- Cross-site data aggregation
- Long-term historical storage
- Advanced analytics and AI
- Integration with MES, ERP, and BI tools
Edge systems alone struggle to provide global visibility across factories.
5. Security and Data Control
Industrial data often includes:
- Production metrics
- Proprietary processes
- Sensitive operational data
Edge processing allows:
- Local data isolation
- Reduced exposure surface
- Fine-grained control over what leaves the site
A hybrid approach minimizes risk while still enabling cloud insights.
When Edge-First Architecture Makes Sense
Edge-first industrial data acquisition is ideal when:
- Real-time monitoring is required
- Network reliability is uncertain
- Data volume is high
- Local autonomy is critical
- Cost control is a priority
Most factory-floor data acquisition scenarios fall into this category.
When Cloud-First Architecture Works
Cloud-first approaches can be effective when:
- Data rates are low
- Latency is not critical
- Sites are well-connected
- Analytics and reporting are the main goal
Examples include energy monitoring, environmental data, or batch reporting systems.
The Reality: Hybrid Edge–Cloud Architecture
In practice, the most effective industrial data acquisition systems are hybrid.
A hybrid architecture typically works as follows:
- Edge layer collects and preprocesses data
- Critical logic runs locally
- Filtered, structured data is sent to the cloud
- Cloud systems handle analytics, storage, and visualization
This model delivers:
- Low latency
- High reliability
- Scalable analytics
- Controlled costs
Hybrid architecture combines the strengths of both worlds.
Architectural Best Practices for Hybrid Data Acquisition
To design an effective hybrid system:
- Keep protocol handling at the edge
- Normalize data before transmission
- Use standard APIs between edge and cloud
- Avoid vendor lock-in
- Design for incremental expansion
These principles allow systems to evolve without major redesign.
Cost Implications: Edge vs Cloud
A common misconception is that cloud-based data acquisition is cheaper.
In reality:
- Bandwidth costs accumulate
- Cloud compute scales with data volume
- Storage costs grow continuously
Edge processing reduces long-term operational expenses by controlling what data is transmitted and stored.
How the Right Architecture Supports Industrial Growth
As operations scale:
- New machines are added
- Data requirements increase
- Integration demands grow
A well-designed industrial data acquisition architecture ensures that growth does not require system replacement—only extension.
Conclusion
The question is not edge or cloud, but how to combine them effectively.
Industrial data acquisition systems must balance real-time performance, reliability, scalability, and cost. Edge-first, cloud-enabled architectures provide the flexibility required for modern industrial environments.
Choosing the right architecture early prevents technical debt and enables long-term success.